Often when you're generating meshes you'll have lots of loops and recursive components - that makes them idea for parallel architectures!
Say hello to `WebGPU`!
Your friendly tool for generating meshes quickly and easily on the GPU.
The WebGPU API has a `compute` pipeline - so you can generate meshes without all the issues of a graphics pipeline (vertex and fragment stages) - using lots of bodges and hacky tricks to get things to work.
Instead, the compute pipeline is a clean and compact way for you to perform parallel computations with no mess.
Few key points about why mesh generation:
• On Vulkan (native API) you have the geometry shader so you can generate/modify mesh data in the graphics pipeline (don't have this with WebGPU API - instead you have the compute shader)
• Challenge is making the mesh generation/update workload is distributed across the GPU threads (take advantage of atomics and buffer indexes)
• Atomic let us manage the parallel complexity - so a thread picks a single triangle. The atomic returns the index into the vertex buffer array - this index is unique to this thread - so there isn't any problems with different threads trying to read and write to the same location.
Compute Mesh Generation
Let's start simple - just get the things running and generate a mesh with 2 triangles.
For each vertex, we'll have a position, normal and color - each are 4 floats each (vec4) to avoid any alignment issues. Also just to get started, we'll just generate a triangle-list (only triangle buffer) - won't generate a seperate index buffer. So every 3 vertices in the buffer makes a triangle. If there are 9 vertices there is 3 triangles.
<?php
console.log('WebGPU Compute Mesh Generation Example (2 Triangles)');
if (!navigator.gpu) { log("WebGPU is not supported (or is it disabled? flags/settings)"); return; }
const adapter = await navigator.gpu.requestAdapter();
const device = await adapter.requestDevice();
// GPU Data Buffers (Data on GPU)
// Counter for how many triangles we have
const buffer0 = new Uint32Array([ 0 ] );
const gbuffer0 = device.createBuffer({ size: buffer0.byteLength, usage: GPUBufferUsage.STORAGE | GPUBufferUsage.COPY_DST | GPUBufferUsage.COPY_SRC });
device.queue.writeBuffer(gbuffer0, 0, buffer0);
const MAX_VERTEX_BUFFER_SIZE = 50; // large buffer
const EACH_VERTEX_SIZE = 12; // each vertex is 12 floats (pos, col, normal)
// Array of triangles (holds our generated mesh)
const buffer1 = new Float32Array( Array( MAX_VERTEX_BUFFER_SIZE * EACH_VERTEX_SIZE ).fill(0) );
const gbuffer1 = device.createBuffer({ size: buffer1.byteLength, usage: GPUBufferUsage.VERTEX | GPUBufferUsage.STORAGE | GPUBufferUsage.COPY_DST | GPUBufferUsage.COPY_SRC });
device.queue.writeBuffer(gbuffer1, 0, buffer1);
// Layout for the pipeline and the shader
// Bind group layout and bind group
const bindGroupLayout = device.createBindGroupLayout({
entries: [ {binding: 0, visibility: GPUShaderStage.COMPUTE, buffer: {type: "storage"} },
{binding: 1, visibility: GPUShaderStage.COMPUTE, buffer: {type: "storage"} }
]
});
const bindGroup = device.createBindGroup({
layout: bindGroupLayout,
entries: [ {binding: 0, resource: {buffer: gbuffer0 }},
{binding: 1, resource: {buffer: gbuffer1 }}
]
});
// Compute shader code
const computeShader = `
struct Vertex {
position : vec4<f32>, // xyzw
color : vec4<f32>, // rgba
normal : vec4<f32> // xyzw
}
@group(0) @binding(0) var<storage, read_write> buf0 : atomic<u32>;
// Maximum number of vertices (triangle-list)
@group(0) @binding(1) var<storage, read_write> buf1 : array<Vertex, ${MAX_VERTEX_BUFFER_SIZE}>;
@compute @workgroup_size(256, 1)
fn main(@builtin(global_invocation_id) globalId : vec3<u32>,
@builtin(local_invocation_id) localId : vec3<u32>,
@builtin(workgroup_id) workgroupId : vec3<u32>,
@builtin(num_workgroups) workgroupSize : vec3<u32>
)
{
// Calculate total number of triangles
let totalTriangles:u32 = TORUS_MAJOR_SEGMENTS * TORUS_MINOR_SEGMENTS * 2u;
if (globalId.x >= totalTriangles) {
return;
}
// Calculate indices for the current triangle
let triIndex:u32 = atomicAdd(&buf0, 1);
// Each triangle is 3 vertices
// Each thread will manage the calculations for '1-triangle' using the 'globalId' to identify
// where the triangle fits in the larger shape model
buf1[triIndex * 3 + 0].position = vec4(0,1,2,0) * f32(globalId.x);
buf1[triIndex * 3 + 1].position = vec4(3,4,5,0) * f32(globalId.x);
buf1[triIndex * 3 + 2].position = vec4(6,7,8,0);
buf1[triIndex * 3 + 0].normal = vec4(0,1,0,0);
buf1[triIndex * 3 + 1].normal = vec4(0,1,0,0);
buf1[triIndex * 3 + 2].normal = vec4(0,1,0,0);
buf1[triIndex * 3 + 0].color = vec4(1,0,0,1);
buf1[triIndex * 3 + 1].color = vec4(0,1,0,1);
buf1[triIndex * 3 + 2].color = vec4(0,0,1,1);
}
`;
// Pipeline setup
const computePipeline = device.createComputePipeline({
layout : device.createPipelineLayout({bindGroupLayouts: [bindGroupLayout]}),
compute: { module : device.createShaderModule({code:computeShader}),
entryPoint: "main" }
});
{
// Commands submission
const commandEncoder = device.createCommandEncoder();
const passEncoder = commandEncoder.beginComputePass();
passEncoder.setPipeline(computePipeline);
passEncoder.setBindGroup(0, bindGroup);
passEncoder.dispatchWorkgroups( 16, 1, 1 );
await passEncoder.end();
// Submit GPU commands.
const gpuCommands = commandEncoder.finish();
await device.queue.submit([gpuCommands]);
}
The skeleton code adds 2 triangles to the vertex buffer (
buffer1
) and updates the vertex buffer counter (
buffer0
).
Just used hard coded values for the size of the buffer (large block) - and the defines are constants getting set in the shader using a string literal (i.e., `MAX_VERTEX_BUFFER_SIZE`). Keeps the code more compact.
Debugging, we'll bring the data back to the CPU and print out the values.
//--------------------------------------------------------------------
async function getGPUBuffer( buf, siz, msg, floatType=false )
{
// Note this buffer is not linked to the 'STORAGE' compute (used to bring the data back to the CPU)
const gbufferTmp = device.createBuffer({ size: siz, usage: GPUBufferUsage.COPY_DST | GPUBufferUsage.MAP_READ});
const commandEncoder = device.createCommandEncoder();
// Encode commands for copying buffer to buffer.
commandEncoder.copyBufferToBuffer(
buf, // source buffer
0, // source offset
gbufferTmp, // destination buffer
0, // destination offset
siz // size
);
// Submit GPU commands.
const gpuCommands = commandEncoder.finish();
await device.queue.submit([gpuCommands]);
// Read buffer.
await gbufferTmp.mapAsync(GPUMapMode.READ);
const arrayBuffer = gbufferTmp.getMappedRange();
var arr = 0;
if ( floatType ) arr = Array.from( new Float32Array(arrayBuffer) );
else arr = Array.from( new Uint32Array(arrayBuffer) );
gbufferTmp.unmap();
console.log(msg + 'array contents:', arr);
return arr;
}
await getGPUBuffer( gbuffer0, buffer0.byteLength, 'num tris ', false );
await getGPUBuffer( gbuffer1, buffer1.byteLength, 'tri data ', true );
Few things to be aware about:
• Size of the buffer for triangles (hardcoded constant of a fixed size)
• Make sure you dispatch enough threads (each thread does 1 triangle)
• Keep track of the vertex structure/size (match when you pass your mesh to the graphics pipeline)
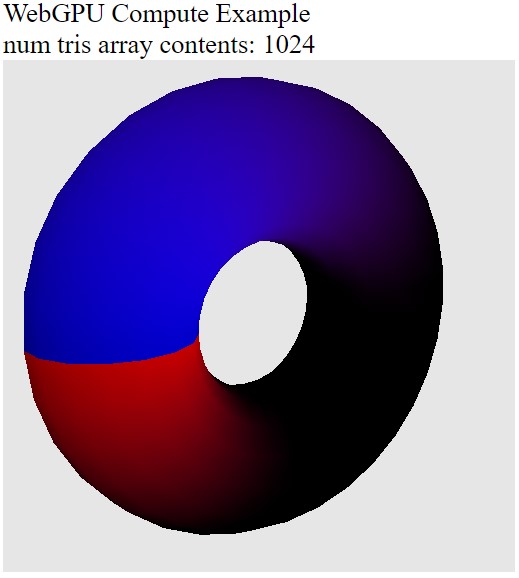
Donut (Torus) Mesh
Now that we've had a little look of how it works - we'll ramp up the calculation in each thread - so it does some actual work!
Going to generate a torus (aka donut looking shape).
As Homer Simpson would said: "Donuts...is there anything they can't do?".
The code is essentially the same as the 2 triangle version - but a lot more calculations have been added to the shader (trignometric functions to work out the position of the triangle for that donut).
<?php
log('WebGPU Compute Example');
if (!navigator.gpu) { log("WebGPU is not supported (or is it disabled? flags/settings)"); return; }
const adapter = await navigator.gpu.requestAdapter();
const device = await adapter.requestDevice();
const MAX_VERTEX_BUFFER_SIZE = 5000;
const EACH_VERTEX_SIZE = 12;
// IN/OUT
const buffer0 = new Uint32Array([ 0 ] );
const gbuffer0 = device.createBuffer({ size: buffer0.byteLength, usage: GPUBufferUsage.STORAGE | GPUBufferUsage.COPY_DST | GPUBufferUsage.COPY_SRC });
device.queue.writeBuffer(gbuffer0, 0, buffer0);
const buffer1 = new Float32Array( Array( MAX_VERTEX_BUFFER_SIZE * EACH_VERTEX_SIZE ).fill(0) );
const gbuffer1 = device.createBuffer({ size: buffer1.byteLength, usage: GPUBufferUsage.VERTEX | GPUBufferUsage.STORAGE | GPUBufferUsage.COPY_DST | GPUBufferUsage.COPY_SRC });
device.queue.writeBuffer(gbuffer1, 0, buffer1);
// Bind group layout and bind group
const bindGroupLayout = device.createBindGroupLayout({
entries: [ {binding: 0, visibility: GPUShaderStage.COMPUTE, buffer: {type: "storage"} },
{binding: 1, visibility: GPUShaderStage.COMPUTE, buffer: {type: "storage"} }
]
});
const bindGroup = device.createBindGroup({
layout: bindGroupLayout,
entries: [ {binding: 0, resource: {buffer: gbuffer0 }},
{binding: 1, resource: {buffer: gbuffer1 }}
]
});
// Compute shader code
const computeShader = `
struct Vertex {
position : vec4<f32>, // xyzw
color : vec4<f32>, // rgba
normal : vec4<f32> // xyzw
}
@group(0) @binding(0) var<storage, read_write> buf0 : atomic<u32>;
// Maximum number of vertices (triangle-list)
@group(0) @binding(1) var<storage, read_write> buf1 : array<Vertex, ${MAX_VERTEX_BUFFER_SIZE}>;
// Torus parameters
const TORUS_MAJOR_RADIUS : f32 = 1.0; // Major radius
const TORUS_MINOR_RADIUS : f32 = 0.5; // Minor radius
const TORUS_MAJOR_SEGMENTS : u32 = 32u; // Number of segments around the major radius
const TORUS_MINOR_SEGMENTS : u32 = 16u; // Number of segments around the minor radius
@compute @workgroup_size(256, 1)
fn main(@builtin(global_invocation_id) globalId : vec3<u32>,
@builtin(local_invocation_id) localId : vec3<u32>,
@builtin(workgroup_id) workgroupId : vec3<u32>,
@builtin(num_workgroups) workgroupSize : vec3<u32>
)
{
// Calculate total number of triangles
let totalTriangles:u32 = TORUS_MAJOR_SEGMENTS * TORUS_MINOR_SEGMENTS * 2u;
if (globalId.x >= totalTriangles) {
return;
}
// Calculate indices for the current triangle
let triIndex:u32 = atomicAdd(&buf0, 1);
let i = triIndex / (TORUS_MINOR_SEGMENTS * 2u);
let j = triIndex % (TORUS_MINOR_SEGMENTS * 2u);
// Check if the buffer can accommodate the new vertices
if (triIndex * 3u >= ${MAX_VERTEX_BUFFER_SIZE} || triIndex >= totalTriangles) {
return;
}
// Determine if we are on the first or second triangle of the quad
let isFirstTriangle = j % 2u == 0u;
let minorIndex = j / 2u;
// Calculate major and minor angles
let majorAngle0 = f32(i) / f32(TORUS_MAJOR_SEGMENTS) * 2.0 * 3.14159265359;
let majorAngle1 = f32(i + 1u) / f32(TORUS_MAJOR_SEGMENTS) * 2.0 * 3.14159265359;
let minorAngle0 = f32(minorIndex) / f32(TORUS_MINOR_SEGMENTS) * 2.0 * 3.14159265359;
let minorAngle1 = f32(minorIndex + 1u) / f32(TORUS_MINOR_SEGMENTS) * 2.0 * 3.14159265359;
// Calculate positions for the vertices
let p0 = vec4<f32>(
(TORUS_MAJOR_RADIUS + TORUS_MINOR_RADIUS * cos(minorAngle0)) * cos(majorAngle0),
(TORUS_MAJOR_RADIUS + TORUS_MINOR_RADIUS * cos(minorAngle0)) * sin(majorAngle0),
TORUS_MINOR_RADIUS * sin(minorAngle0),
1.0
);
let p1 = vec4<f32>(
(TORUS_MAJOR_RADIUS + TORUS_MINOR_RADIUS * cos(minorAngle0)) * cos(majorAngle1),
(TORUS_MAJOR_RADIUS + TORUS_MINOR_RADIUS * cos(minorAngle0)) * sin(majorAngle1),
TORUS_MINOR_RADIUS * sin(minorAngle0),
1.0
);
let p2 = vec4<f32>(
(TORUS_MAJOR_RADIUS + TORUS_MINOR_RADIUS * cos(minorAngle1)) * cos(majorAngle1),
(TORUS_MAJOR_RADIUS + TORUS_MINOR_RADIUS * cos(minorAngle1)) * sin(majorAngle1),
TORUS_MINOR_RADIUS * sin(minorAngle1),
1.0
);
let p3 = vec4<f32>(
(TORUS_MAJOR_RADIUS + TORUS_MINOR_RADIUS * cos(minorAngle1)) * cos(majorAngle0),
(TORUS_MAJOR_RADIUS + TORUS_MINOR_RADIUS * cos(minorAngle1)) * sin(majorAngle0),
TORUS_MINOR_RADIUS * sin(minorAngle1),
1.0
);
// Assign vertex data
if (isFirstTriangle) {
buf1[triIndex * 3 + 0].position = p0;
buf1[triIndex * 3 + 1].position = p1;
buf1[triIndex * 3 + 2].position = p2;
buf1[triIndex * 3 + 0].normal = normalize(p0);
buf1[triIndex * 3 + 1].normal = normalize(p1);
buf1[triIndex * 3 + 2].normal = normalize(p2);
} else {
buf1[triIndex * 3 + 0].position = p0;
buf1[triIndex * 3 + 1].position = p2;
buf1[triIndex * 3 + 2].position = p3;
buf1[triIndex * 3 + 0].normal = normalize(p0);
buf1[triIndex * 3 + 1].normal = normalize(p2);
buf1[triIndex * 3 + 2].normal = normalize(p3);
}
// Assign colors (simple gradient based on major angle)
let color0 = vec4<f32>(f32(i) / f32(TORUS_MAJOR_SEGMENTS), 0.0, 1.0 - f32(i) / f32(TORUS_MAJOR_SEGMENTS), 1.0);
let color1 = vec4<f32>(f32(i + 1u) / f32(TORUS_MAJOR_SEGMENTS), 0.0, 1.0 - f32(i + 1u) / f32(TORUS_MAJOR_SEGMENTS), 1.0);
if (isFirstTriangle) {
buf1[triIndex * 3 + 0].color = color0;
buf1[triIndex * 3 + 1].color = color1;
buf1[triIndex * 3 + 2].color = color1;
} else {
buf1[triIndex * 3 + 0].color = color0;
buf1[triIndex * 3 + 1].color = color1;
buf1[triIndex * 3 + 2].color = color0;
}
}
`;
// Pipeline setup
const computePipeline = device.createComputePipeline({
layout : device.createPipelineLayout({bindGroupLayouts: [bindGroupLayout]}),
compute: { module : device.createShaderModule({code:computeShader}),
entryPoint: "main" }
});
{
// Commands submission
const commandEncoder = device.createCommandEncoder();
const passEncoder = commandEncoder.beginComputePass();
passEncoder.setPipeline(computePipeline);
passEncoder.setBindGroup(0, bindGroup);
passEncoder.dispatchWorkgroups( 16, 1, 1 );
await passEncoder.end();
// Submit GPU commands.
const gpuCommands = commandEncoder.finish();
await device.queue.submit([gpuCommands]);
}
//--------------------------------------------------------------------
async function getGPUBuffer( buf, siz, msg, floatType=false )
{
// Note this buffer is not linked to the 'STORAGE' compute (used to bring the data back to the CPU)
const gbufferTmp = device.createBuffer({ size: siz, usage: GPUBufferUsage.COPY_DST | GPUBufferUsage.MAP_READ});
const commandEncoder = device.createCommandEncoder();
// Encode commands for copying buffer to buffer.
commandEncoder.copyBufferToBuffer(
buf, // source buffer
0, // source offset
gbufferTmp, // destination buffer
0, // destination offset
siz // size
);
// Submit GPU commands.
const gpuCommands = commandEncoder.finish();
await device.queue.submit([gpuCommands]);
// Read buffer.
await gbufferTmp.mapAsync(GPUMapMode.READ);
const arrayBuffer = gbufferTmp.getMappedRange();
var arr = 0;
if ( floatType ) arr = Array.from( new Float32Array(arrayBuffer) );
else arr = Array.from( new Uint32Array(arrayBuffer) );
gbufferTmp.unmap();
log(msg + 'array contents:', arr);
return arr;
}
const numTris = await getGPUBuffer( gbuffer0, buffer0.byteLength, 'num tris ', false );
//await getGPUBuffer( gbuffer1, buffer1.byteLength, 'tri data ', true );
console.log('numTris:', numTris );
Not really much to see! But you can look at the raw data to check it's correct.
I know what you're thinking! Look at the raw numbers, are you crazy! Okay, okay, in the next part, we'll add some lines of code that can be piggy backed onto the end of the donut code that takes the donut mesh buffer and draws it!
Drawing Donut (Show me the Donut!)
The following is a bit of code that follows the compute shader code that generated the mesh - it's a small graphics pipeline that renders the triangle-list.
Once you've had a look at the code and it's sort of making sense - it's time to take things further. A few ideas to get the ball rolling and to help you explore and experiment:
• Try generating a few other shapes (modifying the compute shader code)
• Explore marching cube algorithm and integrating it with the compute mesh generation shader
• Try generating vertices and index values seperately (instead of a single triangle-list - vertices and indices)
• Generate multiple mesh data (e.g., vertex data for triangles and an overlaying wiremesh line data)
• Tesselation effect - pass the vertex data to the geometry shader - and each triangle is processed on a seperate thread - generates a new set of triangles for the old triangle (building a new mesh). Use the normal and subdivide the triangle into smaller triangles.
Advanced
• Generate mesh dynamically on the fly each frame (or for each change) - animate the generated mesh (see the mesh change on screen). Call the compute shader each frame (reset the vertex count) - might need to double buffer (one buffer used for generation while another buffer is being used for rendering)
• Continuing with the dynamic mesh generation - generate different 'Level of Detail' (LOD) meshes on the fly (select 1, 2, 3, 4..etc) and the mesh will update to the level of datail (more/less triangles)