Getting started with the WebGPU compute pipeline and compute shaders. The WGSL shader is a small program that runs on the GPU. You'll use JavaScript and the WebGPU API to initialize and configure and control things. The GPU is a very powerful beast, but you have to understand it if you want to take advantage of it power.
On the journey to mastering WebGPU compute - the journey should start with something simple - data read/write to the compute!
The CPU is like an elephant (large and powerful), while the GPU is more like ants, lots and lots of small but less powerful components. Now the reason the GPU overtakes the GPU is this small parallel aspect. Imagine you had to add 2 numbers - very easy task - now if you had to do this a million times - the CPU would have to repeat the process again and again a million times - while the GPU can do it in parallel in a single go!
Now this is a bit of an oversimplification - but it puts the point across - we're cutting through a lot of things.
WARNING For those who are fairly inexperienced in programming and think of jumping into JavaScript and parallal programming - I'd strongly caution you to go back and get a lot of experience writing small test programs - to get a feel for things. A lot of programming is about 'debugging' - which mostly comes from experience. Otherwise, when things don't work - it'll be like jumping out of a plane without a parachute.
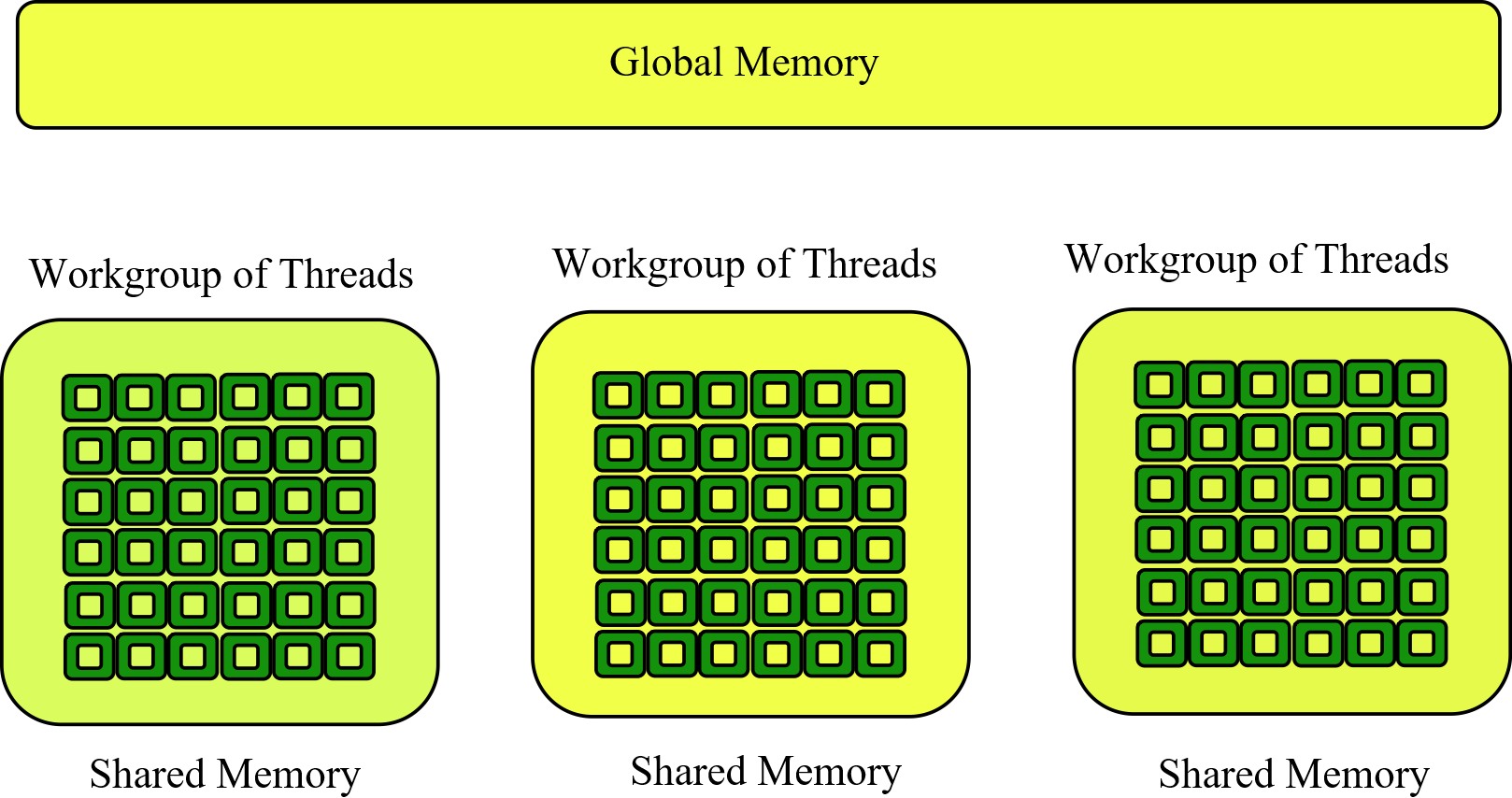
Cores, Threads and Memory
Are Cores and Threads the Same? No, on a GPU, a core is not the same as a thread. The two concepts refer to different aspects of GPU architecture and functionality.
• Core (or tiny processor) is the basic processing unit of the GPU (actual hardwar for doing the calculations).
• Thread is a lightweight processes that execute on the cores (might have multiple threads running on a single core).
Memory is a big challenge on the GPU and one of the reasons not all algorithms are suitable for parallel architectures. While having a large number of threads read from a fixed memory location - having threads read and write to the same location causes problems as the GPU has limited (simplified) memory synchronisation logic. The benefits from locking and stalling the small thread can make the GPU perform considerably slower than if the same code executed on the CPU.
Threads and cores - large number of cores but there is even a larger number of threads. However, the threads are highly coupled work in 'parallel' (do the operations synchronously).
Dispatch number (grid size) defines the total number of workgroups launched to execute a task, determining how the workload is divided across the GPU. Together, these parameters control the parallel execution of tasks, with the workgroup size optimizing local execution efficiency and the dispatch number scaling the task across the GPU's resources.
Compute Group Sizes and Dispatch Groups
• You define the group sizes in the WGSL compute shader (e.g.,
@compute @workgroup_size(1)
).
• You say how man of these grous you want to run using the WebGPU API (e.g.,
dispatchWorkgroups(..)
).
Inside the compute shader you have access to
builtin
variables that let the shader know information about its workgroup (e.g., index).
When specifying the group size and how many to dispatch - you have control - so if you don't dispatch enough threads - the calculation won't be correct.
Why Have Thread Groups?
Unlike the graphics shaders, the compute shader requires more control - as the execution logic can be more exotic and complicate so you might want to break this up to help relieve bottlnecks and synchronous processing logic problems.
Group together the compute tasks into 'groups' (known as workgroups).
Memory
GPU memory is designed to handle high-throughput data access for efficient parallel processing (with a hierarchy that includes global memory, caches, and shared memory). Global memory, often the largest and slowest, is used for general-purpose data storage accessible by all GPU cores but has higher latency. To mitigate this, GPUs employ caches, such as L1 and L2 caches, which store frequently accessed data to reduce latency and improve performance.
Shared memory is a small high-speed memory space accessible by threads within the same block, enabling fast data exchange and synchronization. Memory access and management on a GPU are optimized through techniques like memory coalescing, which aligns memory access patterns to maximize bandwidth and minimize latency, ensuring efficient utilization of the GPU's computational resources.
Threads and memory. Threads grouped together that execute a given portion of a task simultaneously within the same block of shared memory.
Single Thread on GPU
For example, if you specify a workgroup size of 1 (
workgroup_size(1)
) and only dispatch a single workgroup (
dispatchWorkgroups(1)
) then only a single thread will run.
The first example, does this - it is only a single thread that has a single memory location (floating point).
We encapsule the example in a function called
main()
. The function is
async
so that we can use
await
(certain initializtion and creation functions are asynchronous - returning a promise so to wait until they're ready, you can use the
The wgsl compute shader (this isn't 'JavaScript') - it is written in the WebGPU Shader Language (WGSL). The shader contents is just text and can be loaded from an external file or simply included as a text variable.
<?php
struct Data { value : f32 };
@group(0) @binding(0) var<storage, read_write> data : Data;
@compute @workgroup_size(1)
fn main( @builtin(global_invocation_id) global_id : vec3<u32>) {
data.value += 1.0;
}
A structure is used for the data called
Data
so you can define the layout of the data in memory. The group and binding is to link to the correct buffer (memory) which you create and link later. The program entry point is
main
- you pass this name to the compute shader pipeline as the 'entry point'.
The shader is included in the file like this (constant string):
const wgslcompute = `
struct Data { value : f32 };
@group(0) @binding(0) var<storage, read_write> data : Data; // you could use 'f32' instead of 'Data' here (if you didn't want to use a structure).
@compute @workgroup_size(1)
fn main( @builtin(global_invocation_id) global_id : vec3<u32>) {
data.value += 1.0;
}
`;
The following compiles the shader and gives the handle.
Setup a block of memory on the GPU (i.e., GPU memory buffer). For this example the memory is only a single floating point (4 bytes). It's important to set the required usage flags. So the memory can be accessed by the compute shader we add the flag
GPUBufferUsage.STORAGE
. Also so we can read and write to the memory (copy source and destination) we set the
GPUBufferUsage.COPY_SRC
and
GPUBufferUsage.COPY_DST
flags.
<?php
// Create a buffer to store data
const bufferSize = 4; // Size of buffer in bytes (float is 4 bytes)
const bufferA = device.createBuffer({
size: bufferSize,
usage: GPUBufferUsage.STORAGE | GPUBufferUsage.COPY_SRC | GPUBufferUsage.COPY_DST,
});
Need to link things together - by defining the ins and outs of the compute shader.
After the calculation has been done - we can't just access the memory. We need to copy it across to a temporary staging location before copying it back to the CPU. This requires the
GPUBufferUsage.MAP_READ
flag when the memory buffer is created.
If a buffer usage contains the flag
MapRead
the only other allowed usage is
CopyDst
. This means you can't have the memory used on the compute shader with the
Storage
flag and the
MapRead
flag. As a workaround, we use a temporary staging memory block.
Data is in our staging memory. Lock the GPU memory using the
mapAsync
so it can be copied from the GPU memory to CPU. After it's copied back we send it to the debug console window.
<?php
// Map and read buffer
await stagingBuffer.mapAsync(GPUMapMode.READ);
const arrayBuffer = stagingBuffer.getMappedRange();
const data = new Float32Array(arrayBuffer);
console.log("Value after computation:", data[0]);
// Clean up
stagingBuffer.unmap();
}
main();
Things to Try
While the example is only simple it's an excellent starting point and covers a number of crucial components (allocating memory, creating pipelines and performing calculations on the GPU using a WGSL compute shader).
• Try other number formats (instead of a float use an unsigned integer)
• Perform a more complicated calculation on the shader (instead of just adding a number) - try some trigonometric functions
• Instead of a single float (4 bytes), allocate a buffer for more values (2 floats which is 8 bytes) - assign them values in the compute shader and read them back
• Assign a larger buffer with multiple data types and define a structure on the compute shader that matches (again allocate values and perform calculations and read back the data to the CPU to check they match). Introduction into the topic of data and structure 'alignment'.