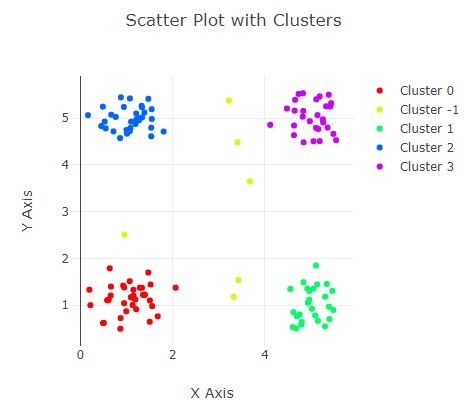
DBSCAN is a density-based clustering algorithm. Finds clusters of dense regions of data points while ignoring the low-density areas (considering them as noise).
Educational/test example - DBSCAN runs on a single thread (not taking advantage of the parallel GPU).
• Algorithm and steps
• Buffers in/out
• Test data (4 distinct groups with some outlier noise points)
• Reading back the data and plotting the clusters on a chart
Works well for noisy datasets. Can identity Outliers easily. Clusters can take any irregular shape unlike K-Means where clusters are more or less spherical.
Of course, it depends on the data. Does not work very well for sparse datasets or datasets with varying density. Sensitive to eps and minPts parameters. As demonstrated here, not easy to partition the basic algorithm onto multiple cores/threads. Nevertheless, it does show the key points of the algorithm, compute setup, and race condition issues when the algorithm isn't setup correctly.
See the resources and links for an alternative 'modified' version that sets each 'point' search to a seperate thread. Gives not results and works most of the time - but due to the nature of the GPU and lack of synchronisation (threads don't necessarily run in order) - causing the result to occasionally be wrong. While some algorithms may seems to run on parallel architectures - it doesn't mean they're robust and give the correct result.
Complete Code
const NUM_POINTS = 128;
const NUM_CLUSTERS = 4;
const wgslcompute = `
// Define the number of data points and clusters
const NUM_POINTS = ${NUM_POINTS};
const NUM_CLUSTERS = ${NUM_CLUSTERS};
// Parameters for DBSCAN
const EPSILON: f32 = 0.75; // Radius to consider for neighborhood
const MIN_POINTS: u32 = 5; // Minimum number of points to form a cluster
@group(0) @binding(0) var<storage, read_write> pointsBuffer : array< vec2<f32>, ${NUM_POINTS}>;
@group(0) @binding(1) var<storage, read_write> pointClusterBuffer : array< i32, ${NUM_CLUSTERS} >; // initialized -1, otherwise index into the cluster
@group(0) @binding(2) var<storage, read_write> clusterCounter : i32; // initialized to 0
// Helper function to calculate the Euclidean distance between two points
fn distance(p1: vec2<f32>, p2: vec2<f32>) -> f32 {
let dx: f32 = p1.x - p2.x;
let dy: f32 = p1.y - p2.y;
return sqrt(dx * dx + dy * dy);
}
@compute @workgroup_size(1) // WARNING ONLY SINGLE THREAD
fn main(@builtin(global_invocation_id) globalId : vec3<u32>,
@builtin(local_invocation_id) localId : vec3<u32>,
@builtin(workgroup_id) workgroupId : vec3<u32>,
@builtin(num_workgroups) workgroupSize : vec3<u32>
)
{
let pointIndex: u32 = localId.x; // WARNING ONLY SINGLE THREAD
for (var pointIndex:u32=0u; pointIndex<NUM_POINTS; pointIndex++)
{
// Step 1: Find all points in the neighborhood of the current point
var neighborCount: u32 = 0;
var neighbors: array<u32, ${NUM_POINTS}>;
for (var i: u32 = 0u; i < NUM_POINTS; i = i + 1u) {
if ( i== pointIndex ) { continue; }
if (distance(pointsBuffer[pointIndex], pointsBuffer[i]) <= EPSILON) {
neighbors[neighborCount] = i;
neighborCount = neighborCount + 1u;
}
}
// Step 2: Mark point as noise if not enough neighbors
if (neighborCount < MIN_POINTS) {
pointClusterBuffer[pointIndex] = -1; // Mark as noise
continue;
}
// Step 3: Otherwise, start a new cluster or join an existing one
var clusterId: i32 = -1;
for (var i: u32 = 0u; i < neighborCount; i = i + 1u) {
let neighborIndex: u32 = neighbors[i];
let neighborCluster: i32 = pointClusterBuffer[neighborIndex];
if (neighborCluster != -1) {
clusterId = neighborCluster;
break;
}
}
if (clusterId == -1) {
clusterId = clusterCounter;
clusterCounter++;
}
// Step 4: Assign the cluster ID to the point and all its neighbors
pointClusterBuffer[pointIndex] = clusterId;
for (var i: u32 = 0u; i < neighborCount; i = i + 1u) {
let neighborIndex: u32 = neighbors[i];
pointClusterBuffer[neighborIndex] = clusterId;
}
}//for loop
}
`;
// Initialize WebGPU
const adapter = await navigator.gpu.requestAdapter();
const device = await adapter.requestDevice();
// Create buffers for data points and cluster centers
const pointsBuffer = device.createBuffer({
size: NUM_POINTS * 8, // 2 floats per point
usage: GPUBufferUsage.STORAGE | GPUBufferUsage.COPY_SRC | GPUBufferUsage.COPY_DST
});
const pointClusterIndexes = device.createBuffer({
size: NUM_POINTS * 4, // i32 index for each point - which cluster it belongs (index into cluster) 0 - NUM_CLUSTERS-1
usage: GPUBufferUsage.STORAGE | GPUBufferUsage.COPY_SRC | GPUBufferUsage.COPY_DST
});
// ------------------------------------------------
// Generate random data points
const pointsData = [];
// Define the number of points and clusters
const POINTS_PER_CLUSTER = NUM_POINTS / NUM_CLUSTERS;
// Define the centers of the clusters
const centers = [
{ 'x': 1.0, 'y': 1.0 },
{ 'x': 5.0, 'y': 1.0 },
{ 'x': 1.0, 'y': 5.0 },
{ 'x': 5.0, 'y': 5.0 },
];
// Define the spread (standard deviation) of the points around each cluster center
const spread = 1.1;
// Generate random data points
for (let i = 0; i < NUM_CLUSTERS; i++) {
const center = centers[i];
for (let j = 0; j < POINTS_PER_CLUSTER; j++) {
const xx = center.x + (Math.random() - 0.5) * spread;
const yy = center.y + (Math.random() - 0.5) * spread;
pointsData.push( xx, yy );
}
}
// Add noise
for (let i = 0; i < pointsData.length; i++) {
if ( Math.random() < 0.9 ) continue;
pointsData[ i ] = Math.random() * 5.0;
}
// -----------------------------------------------
// Copy data points to the GPU buffer
const pointsArrayBuffer = new Float32Array(pointsData);
device.queue.writeBuffer(pointsBuffer, 0, pointsArrayBuffer);
// -----------------------------------------------
const pointIndexes = [];
for (let i = 0; i < NUM_POINTS; i++) {
pointIndexes.push(-1); // initialize to invalid value
}
const pointIndexesBuf = new Int32Array(pointIndexes);
device.queue.writeBuffer(pointClusterIndexes, 0, pointIndexesBuf);
// -----------------------------------------------
const clusterCounterBuffer = new Int32Array(1);
clusterCounterBuffer[0] = 0;
const clusterCountGPU = device.createBuffer({ size: 4, usage: GPUBufferUsage.STORAGE | GPUBufferUsage.COPY_SRC | GPUBufferUsage.COPY_DST } );
device.queue.writeBuffer(clusterCountGPU, 0, clusterCounterBuffer);
// -----------------------------------------------
const bindGroupLayout = device.createBindGroupLayout({
entries: [ {binding: 0, visibility: GPUShaderStage.COMPUTE, buffer: {type: "storage"} },
{binding: 1, visibility: GPUShaderStage.COMPUTE, buffer: {type: "storage"} },
{binding: 2, visibility: GPUShaderStage.COMPUTE, buffer: {type: "storage"} },
]
});
const bindGroup = device.createBindGroup({
entries: [
{ binding: 0, resource: { buffer: pointsBuffer } },
{ binding: 1, resource: { buffer: pointClusterIndexes } },
{ binding: 2, resource: { buffer: clusterCountGPU } },
],
layout: bindGroupLayout
});
const computeShaderModule = device.createShaderModule({
code: wgslcompute,
});
const computePipe = device.createComputePipeline({
layout : device.createPipelineLayout({bindGroupLayouts: [bindGroupLayout]}),
compute: { module : computeShaderModule,
entryPoint: "main" }
});
// Execute the compute shader
const commandEncoder = device.createCommandEncoder();
const passEncoder = commandEncoder.beginComputePass();
passEncoder.setPipeline(computePipe);
passEncoder.setBindGroup(0, bindGroup );
passEncoder.dispatchWorkgroups(1);
await passEncoder.end();
const gpuCommands = commandEncoder.finish();
await device.queue.submit([gpuCommands]);
// Read back cluster centers from the GPU buffer
// ------------------------------------------------------------------
// Note this buffer is not linked to the 'STORAAGE' compute (used to bring the data back to the CPU)
const bufferTmp = new Float32Array( pointIndexesBuf.length );
const gbufferTmp = device.createBuffer({ size: pointIndexesBuf.byteLength, usage: GPUBufferUsage.COPY_DST | GPUBufferUsage.MAP_READ});
//device.queue.writeBuffer(gbuffer3, 0, buffer3);
const commandEncoder2 = device.createCommandEncoder();
// Encode commands for copying buffer to buffer.
commandEncoder2.copyBufferToBuffer(
pointClusterIndexes, // source buffer
0, // source offset
gbufferTmp, // destination buffer
0, // destination offset
bufferTmp.byteLength // size
);
// Submit GPU commands.
const gpuCommands2 = commandEncoder2.finish();
await device.queue.submit([gpuCommands2]);
// Map and read buffer
await gbufferTmp.mapAsync(GPUMapMode.READ);
const arrayBuffer0 = gbufferTmp.getMappedRange();
const dataTmp = new Int32Array(arrayBuffer0);
const buf0 = Array.from(dataTmp);
console.log('arrayBuffer0 :', dataTmp[0] );
// Clean up
gbufferTmp.unmap();
//for (let i=0; i<100; i++)
console.log("Value after computation:", buf0[0]);
// ---------------------------------
const clusters = [];
for (let i = 0; i < NUM_POINTS; i++) {
const x = pointsData[i * 2];
const y = pointsData[i * 2 + 1];
const clusterIndex = buf0[ i ]; // The cluster index is stored after the data points
clusters.push({ x, y, clusterIndex });
}
let promise = await fetch('https://cdn.plot.ly/plotly-latest.min.js');
let text = await promise.text();
let script = document.createElement('script');
script.type = 'text/javascript';
script.async = false;
script.innerHTML = text;
document.body.appendChild(script);
let div = document.createElement('div');
document.body.appendChild( div );
div.id = 'scatter-plot';
// Get unique cluster indices and assign colors
const uniqueClusterIndices = [...new Set(clusters.map(cluster => cluster.clusterIndex))];
const colors = uniqueClusterIndices.map((index, i) => `hsl(${i * 360 / uniqueClusterIndices.length}, 100%, 50%)`);
// Create traces for each cluster
const traces = uniqueClusterIndices.map((clusterIndex, index) => {
const clusterPoints = clusters.filter(cluster => cluster.clusterIndex === clusterIndex);
return {
x: clusterPoints.map(point => point.x),
y: clusterPoints.map(point => point.y),
mode: 'markers',
type: 'scatter',
name: `Cluster ${clusterIndex}`,
marker: { color: colors[index] }
};
});
// Plot the data
Plotly.newPlot('scatter-plot', traces, {
title: 'Scatter Plot with Clusters',
xaxis: { title: 'X Axis' },
yaxis: { title: 'Y Axis' }
});
Things to Try
• Try modifying the algorithm to make the single thread version more parallel (note some parts of the algorithm are parallel while others aren't) - so you can calculate outliers using the GPU but the cluster ID assignments would be done differently.
• Try running the algorithm in 'iterations' on the GPU (so for large arrays of tens of thousands it doesn't 'stall' the compute thread)
• Try changing the configuration parameters for the 'EPSILON' and 'MIN_POINTS'
• Try other test cluster patterns
• Load in a real-world external data set and see how it performs on the clustering algorithm
• Try expanding the algorithm to '3d' data set (x, y and z)