Vectors and matrices are fundamental in computer science for efficiently handling data, enabling operations such as transformations, optimizations and simulations in areas like machine learning, graphics, and scientific computing. Their structured representation of data allows for powerful algorithms that can process and analyze information at high speeds, making them crucial tools in both theoretical and applied computing.
Vector and matrix mathematics is such a big things - but it's also a really easy thing to perform cetain operationslike matrix-multipilcation quickly and efficienly on the GPU.
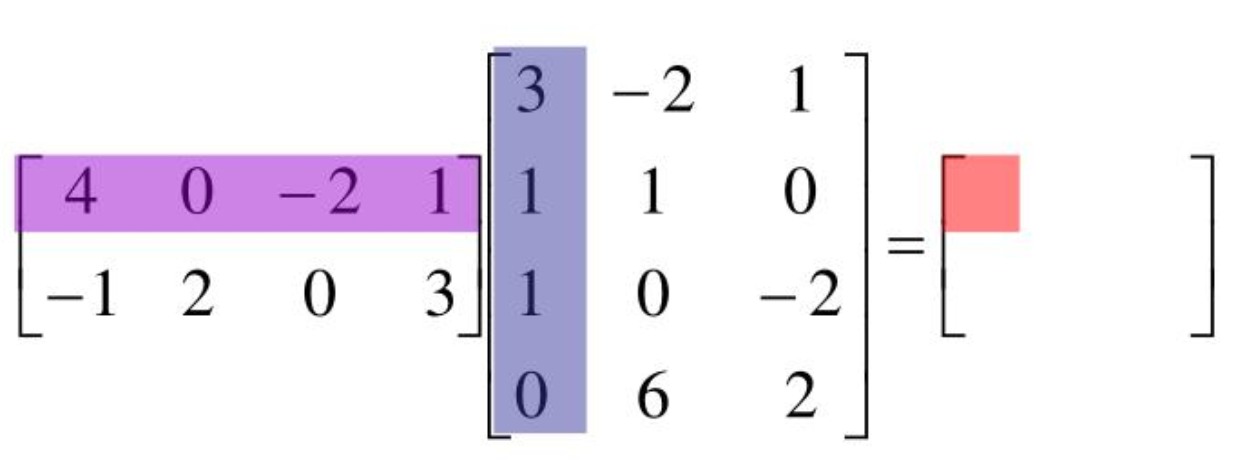
Matrix multiplication process - arrays of numbers.
<?php
let div = document.createElement('div');
document.body.appendChild( div );
div.style['font-size'] = '20pt';
function log( s )
{
console.log( s );
let args = [...arguments].join(' ');
div.innerHTML += args + '<br>';
}
log('WebGPU Compute Example');
if (!navigator.gpu) {
log("WebGPU is not supported (or is it disabled? flags/settings)");
return;
}
const adapter = await navigator.gpu.requestAdapter();
const device = await adapter.requestDevice();
// First Matrix
const firstMatrix = new Float32Array([
2, // rows
4, // columns
1,2,3,4, // array data
5,6,7,8
]);
log('matrix a (2x4):', firstMatrix.slice(2) );
const bufferFirstMatrix = device.createBuffer({
mappedAtCreation: true,
size: firstMatrix.byteLength,
usage: GPUBufferUsage.STORAGE
});
const arrayBufferFirstMatrix = bufferFirstMatrix.getMappedRange();
new Float32Array(arrayBufferFirstMatrix).set(firstMatrix);
bufferFirstMatrix.unmap();
// Second Matrix
const secondMatrix = new Float32Array([
4, // rows
2, // columns
1,2, // array data
3,4,
5,6,
7,8
]);
log('matrix b (4x2):', secondMatrix.slice(2) );
const bufferSecondMatrix = device.createBuffer({
mappedAtCreation: true,
size: secondMatrix.byteLength,
usage: GPUBufferUsage.STORAGE
});
const arrayBufferSecondMatrix = bufferSecondMatrix .getMappedRange();
new Float32Array(arrayBufferSecondMatrix).set(secondMatrix);
bufferSecondMatrix .unmap();
// Result Matrix
const resultMatrixBufferSize =
// 2 is because - first 2 elements are used to define the matrix size
Float32Array.BYTES_PER_ELEMENT * ( 2 + firstMatrix[0] * secondMatrix[1] );
const resultMatrixBuffer = device.createBuffer({
size: resultMatrixBufferSize,
usage: GPUBufferUsage.STORAGE | GPUBufferUsage.COPY_SRC
});
// Bind group layout and bind group
const bindGroupLayout = device.createBindGroupLayout({
entries: [ {binding: 0, visibility: GPUShaderStage.COMPUTE,
buffer: {type: "read-only-storage"} },
{binding: 1, visibility: GPUShaderStage.COMPUTE,
buffer: {type: "read-only-storage"} },
{binding: 2, visibility: GPUShaderStage.COMPUTE,
buffer: {type: "storage"} }
]
});
const bindGroup = device.createBindGroup({
layout: bindGroupLayout,
entries: [ {binding: 0, resource: {buffer: bufferFirstMatrix }},
{binding: 1, resource: {buffer: bufferSecondMatrix}},
{binding: 2, resource: {buffer: resultMatrixBuffer }}
]
});
// Compute shader code
const computeShader = `
struct Matrix {
size : vec2<f32>,
numbers: array<f32>,
};
@group(0) @binding(0) var<storage, read> firstMatrix : Matrix;
@group(0) @binding(1) var<storage, read> secondMatrix : Matrix;
@group(0) @binding(2) var<storage, read_write> resultMatrix : Matrix;
/*
8x8 is a good approx for a 'dispatch-group' (or a thread-group).
When 'dispatch' is called it creates groups of these groups
*/
@compute @workgroup_size(8, 8)
fn main(@builtin(global_invocation_id) globalId : vec3<u32>,
@builtin(local_invocation_id) localId : vec3<u32>,
@builtin(workgroup_id) workgroupId : vec3<u32>,
@builtin(num_workgroups) workgroupSize : vec3<u32>
)
{
// global_invocation_id is equal to workgroup_id * num_workgroups + local_invocation_id
// e.g.
//var globalId : vec3<u32> = workgroupId * workgroupSize + localId;
// Guard against out-of-bounds work group sizes.
if (globalId.x >= u32(firstMatrix.size.x) || globalId.y >= u32(secondMatrix.size.y)) {
return;
}
resultMatrix.size = vec2<f32>(firstMatrix.size.x, secondMatrix.size.y);
let resultCell = vec2<u32>(globalId.x, globalId.y);
var result = 0.0;
for (var i = 0u; i < u32(firstMatrix.size.y); i = i + 1u) {
let a = i + resultCell.x * u32(firstMatrix.size.y);
let b = resultCell.y + i * u32(secondMatrix.size.y);
result = result + firstMatrix.numbers[a] * secondMatrix.numbers[b];
}
let index = resultCell.y + resultCell.x * u32(secondMatrix.size.y);
resultMatrix.numbers[index] = result;
}
`;
// Pipeline setup
const computePipeline = device.createComputePipeline({
layout : device.createPipelineLayout({bindGroupLayouts: [bindGroupLayout]}),
compute: { module : device.createShaderModule({code:computeShader}),
entryPoint: "main" }
});
// Commands submission
const commandEncoder = device.createCommandEncoder();
const passEncoder = commandEncoder.beginComputePass();
passEncoder.setPipeline(computePipeline);
passEncoder.setBindGroup(0, bindGroup);
const x = Math.ceil(secondMatrix[1] / 8); // X dimension of the grid of workgroups to dispatch.
const y = Math.ceil(secondMatrix[1] / 8); // Y dimension of the grid of workgroups to dispatch.
/*
Dispatch work to be performed with the current GPUComputePipeline
dispatchWorkgroups(workgroupCountX, workgroupCountY, workgroupCountZ)
x,y,z - dimension of the grid of workgroups to dispatch.
Note: number of workgroups to dispatch for each dimension, not the number of shader invocations to perform across each dimension
e.g. This means that if the shader defines an entry point with @workgroup_size(4, 4), and work is dispatched to it with the call computePass.dispatchWorkgroups(8, 8); the entry point will be invoked 1024 times total: Dispatching a 4x4 workgroup 8 times along both the X and Y axes. (4*4*8*8=1024)
*/
passEncoder.dispatchWorkgroups( x, y );
passEncoder.end();
// Get a GPU buffer for reading in an unmapped state.
const readBuffer = device.createBuffer({
size : resultMatrixBufferSize,
usage: GPUBufferUsage.COPY_DST | GPUBufferUsage.MAP_READ
});
// Encode commands for copying buffer to buffer.
commandEncoder.copyBufferToBuffer(
resultMatrixBuffer, // source buffer
0, // source offset
readBuffer, // destination buffer
0, // destination offset
resultMatrixBufferSize // size
);
// Submit GPU commands.
const gpuCommands = commandEncoder.finish();
device.queue.submit([gpuCommands]);
// Read buffer.
await readBuffer.mapAsync(GPUMapMode.READ);
const arrayBuffer = readBuffer.getMappedRange();
log('result a x b:', new Float32Array(arrayBuffer));
log('Remember - first 2 values are the matrix size in the result');
Compute multiplication output for the example below.
Things to Try
• Try multiplying a much larger set of matrices (hundreds or thousands of rows and columns). Calculate the answer on the CPU using JavaScript to compare and check the GPU version is correct (match).
• Try implementing other matrix operations, such as, transpose, scale, identity.