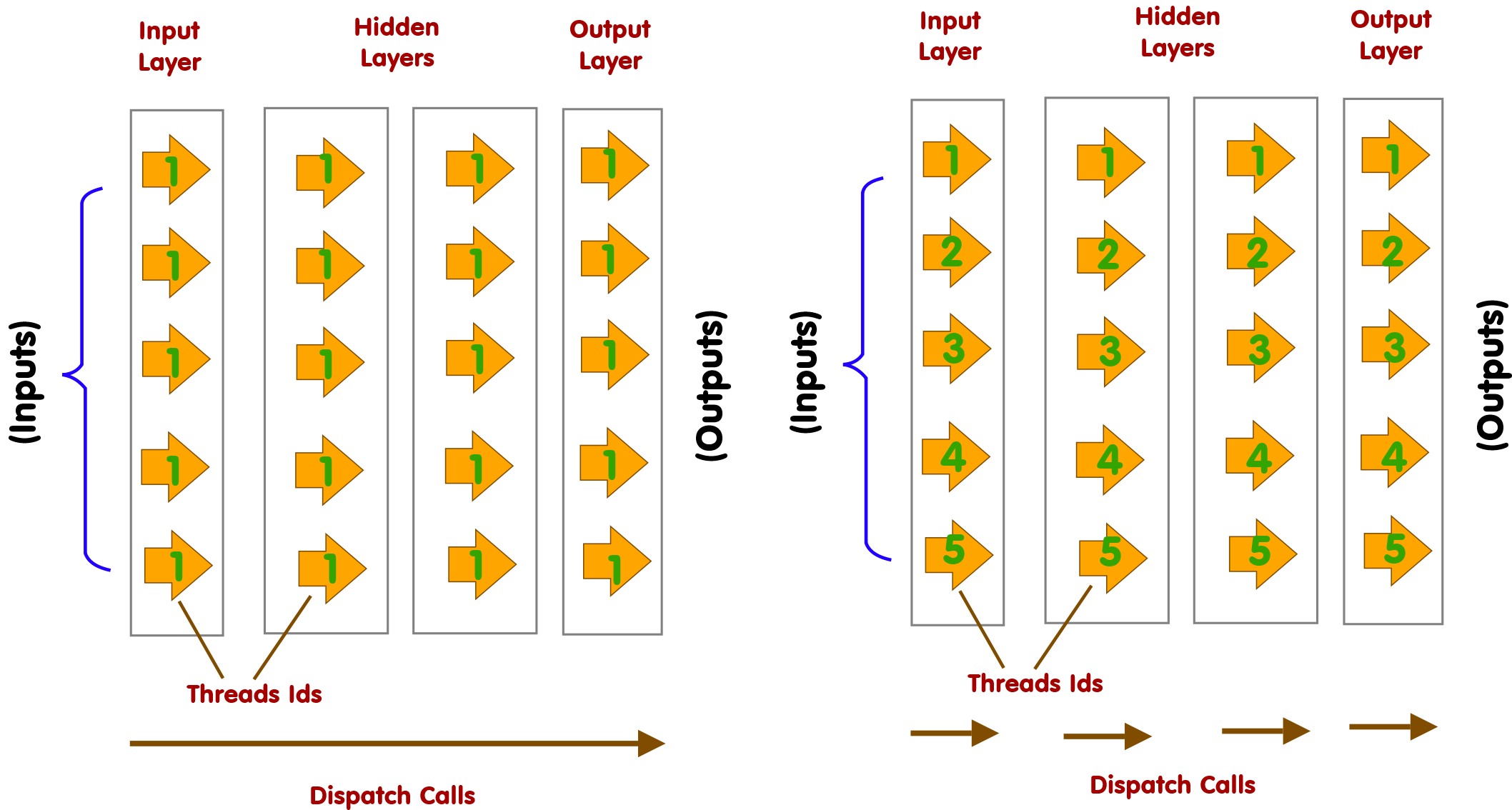
Shift from a single thread to multiple threads on the GPU.
Forward phase (activation) - Single to Multiple Threads
As the input 'propogates' from the input to the output - the neurons near the output cannot perform their calculations until they get the data reaches them.
However, the layers can be processed in parallel (each layer is capable of containing lots of neurons).
Shift from all the layers (Input - Hidden - Output) running on a single thread to splitting the layers across dispatch calls (execute them one after the other). This then lets us distribute the perceptron calculation onto different threads.
Forward propogation - the layers can be grouped together into dispatch calls - this means each neuron in each layer is independent of each other and can be processed concurrently on the GPU without any issues.
Take the single threaded activation function, as shown below, notice that the calculation moves from input to output over the layers.
// excluded accessor/helper functions
....
@compute @workgroup_size(1)
fn main(@builtin(global_invocation_id) global_id: vec3<u32>) {
// single thread
// Hidden to hidden layers (last one is the output layer)
for (var g:u32=0; g<arrayLength( &layers ); g++)
{
if ( g==0)
{
// Input to first hidden layer
for (var k:u32=0; k<layers[0]; k++)
{
// input has no bias
setLayerOutput( 0, k, inputs[k] );
}
}
else
{
for (var n0:u32=0; n0<layers[g]; n0++)
{
var sum = getBias( g, n0 );
for (var n1:u32=0; n1<layers[g-1]; n1++)
{
sum += getLayerOutput( g-1, n1 ) * getWeight( g-1, n1, n0 );
}
setLayerOutput( g, n0, sigmoid(sum) );
}
}
if ( g==arrayLength( &layers )-1 )
{
// Last hidden layer is the output layer
for (var k:u32=0; k<arrayLength( &outputs ); k++)
{
outputs[k] = getLayerOutput( arrayLength(&layers)-1 , k );
}
}
}
}
Shift the compute calculation so it is called per layer, with each layer running the calculation for outputs of that layer in parallel.
First, we modify the dispatch code on the JavaScript side, so it is called for each layer (also pass the layer index to the compute shader).
The following is the modified compute shader that shifts from a single 'thread' to multiple threads. Cut out loops and changed them to the layer index and workgroup number.
@compute @workgroup_size(4) // >= MAX_NEURONS_PER_LAYER (round it to power of 2)
fn main(@builtin(global_invocation_id) global_id: vec3<u32>) {
let k = global_id.x;
// Input to hidden layers (last one is the output layer)
let g:u32 = currentLayer;
//for (var g:u32=0; g<arrayLength( &layers ); g++)
{
if ( g==0)
{
// Input to first hidden layer
//for (var k:u32=0; k<layers[0]; k++)
{
// input has no bias
setLayerOutput( 0, k, inputs[k] );
}
}
else
{
//for (var k:u32=0; k<layers[g]; k++)
{
var sum = getBias( g, k );
for (var n1:u32=0; n1<layers[g-1]; n1++)
{
sum += getLayerOutput( g-1, n1 ) * getWeight( g-1, n1, k );
}
setLayerOutput( g, k, sigmoid(sum) );
}
}
if ( g==arrayLength( &layers )-1 )
{
// Last hidden layer is the output layer
//for (var k:u32=0; k<arrayLength( &outputs ); k++)
{
outputs[k] = getLayerOutput( arrayLength(&layers)-1 , k );
}
}
}
}
Layers with lots of neurons can be executed in parallel - ripple from the input to the output layers.
Backward Phase (Propogation) - Single to Multiple Threads
Let's start by looking at the single threaded propogation algorithm on the compute shader:
@compute @workgroup_size(1)
fn main(@builtin(global_invocation_id) global_id: vec3<u32>) {
// single thread
// *1* Output Errors
// Backpropagate errors from output through hidden layers and store them
for ( var g:u32=arrayLength(&layers)-1; g>0; g-- )
{
// Output layer (last one)
if ( g == arrayLength(&layers)-1 )
{
for ( var k:u32=0; k<layers[ g ]; k++ )
{
let output = getLayerOutput( g, k );
let error = ( output - expected[k] ) * sigmoidDerivative( getLayerOutput( g, k ) );
setError( g, k, error );
}
}
// All hidden layers
else
{
for (var n0:u32=0; n0<layers[g]; n0++)
{
var error = 0.0;
for (var n1:u32=0; n1<layers[g+1]; n1++)
{
let weight = getWeight(g, n0, n1 );
error += weight * getError( g+1, n1 );
}
error = error * sigmoidDerivative( getLayerOutput( g, n0 ) );
setError( g, n0, error );
}
}
}
// *2* Update Weights and Biases
// Update weights and biases for each layer using the error
for (var k:u32=0; k<arrayLength( &layers )-1; k++)
{
for (var n0:u32=0; n0<layers[k]; n0++)
{
// Update the bias
var bias = getBias( k, n0 );
bias -= LEARNING_RATE * getError( k, n0 );
setBias( k, n0, bias );
for (var n1:u32=0; n1<layers[k]; n1++)
{
var weight = getWeight( k, n0, n1 );
weight -= LEARNING_RATE * getError( k+1, n1 ) * getLayerOutput( k, n0 );
setWeight( k, n0, n1, weight );
}
}
}
}
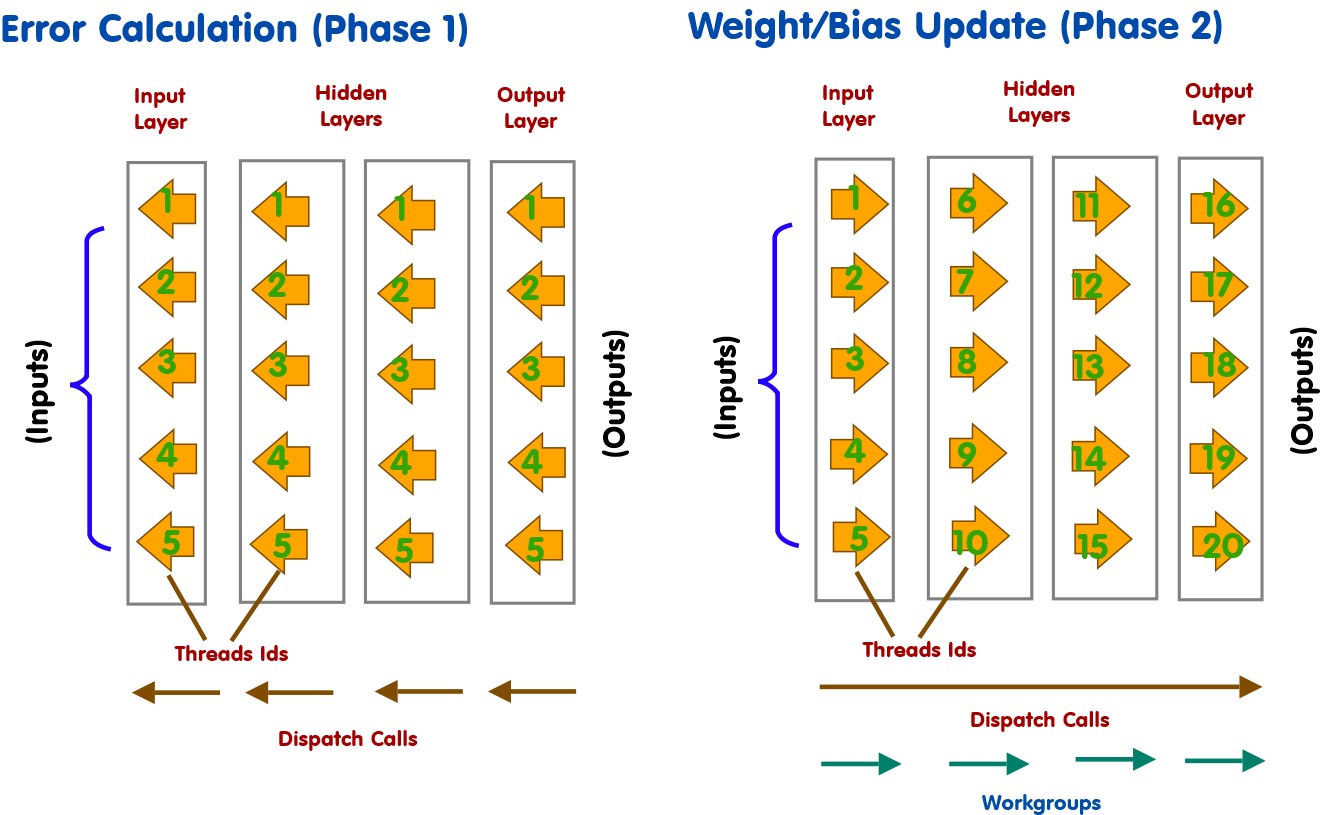
We want to shift from a single compute thread to as many as possible (without breaking the algorithm).
• Split the propogation shader into 2 parts (error calculation and the weight updates)
• Error update we'll do the same as the activation stage and go layer by layer (ripple) the error backwards from the output to the input
Split the backpropogation into 2 phases - gradient/error calculation phase (1) followed by a weight/bias update phase (2).
First, let's look at the updated propogate function, split the compute execution into two main parts. These parts are processed on a layer by layer update so that multiple compute threads can be executed.
@compute @workgroup_size(4) // >= than MAX_NEURONS_PER_LAYER
fn main1(@builtin(global_invocation_id) global_id: vec3<u32>) {
let k = global_id.x;
// *1* Output Errors
// Backpropagate errors from output through hidden layers and store them
//for ( var g:u32=arrayLength(&layers)-1; g>0; g-- ) // shift to layer by layer compute processing
let g:u32 = currentLayer;
{
// Output layer (last one)
if ( g == arrayLength(&layers)-1 )
{
//for ( var k:u32=0; k<layers[ g ]; k++ ) // shift to threads
if ( k < layers[ g ] )
{
let output = getLayerOutput( g, k );
let error = ( output - expected[k] ) * sigmoidDerivative( getLayerOutput( g, k ) );
setError( g, k, error );
}
}
// All hidden layers
else
{
//for (var k:u32=0; k<layers[g]; k++) // -> shift to threads
if ( k < layers[g] )
{
var error = 0.0;
for (var n1:u32=0; n1<layers[g+1]; n1++)
{
let weight = getWeight(g, k, n1 );
error += weight * getError( g+1, n1 );
}
error = error * sigmoidDerivative( getLayerOutput( g, k ) );
setError( g, k, error );
}
}
}
}// end main1
@compute @workgroup_size(4) // >= than MAX_NEURONS_PER_LAYER
fn main2(@builtin(global_invocation_id) global_id: vec3<u32>) {
let g = global_id.x;
// *2* Update Weights and Biases
// Update weights and biases for each layer using the error
//for (var k:u32=0; k<arrayLength( &layers )-1; k++) // -> shift to layer-by-layer compute calls
let k:u32 = currentLayer;
{
//for (var g:u32=0; g<layers[k]; g++) // -> shift to threads
if ( g < layers[k] )
{
// Update the bias
var bias = getBias( k, g );
bias -= LEARNING_RATE * getError( k, g );
setBias( k, g, bias );
for (var n1:u32=0; n1<layers[k]; n1++)
{
var weight = getWeight( k, g, n1 );
weight -= LEARNING_RATE * getError( k+1, n1 ) * getLayerOutput( k, g );
setWeight( k, g, n1, weight );
}
}
}
}// end main2
Things to consider - workgroup size has a limit of 256. So for very large networks you'd have to add in some extra code to distribute the work over multiple dispatch calls.
More Threads? (Multiple Workgroups)
We push things a bit further by taking into acount the layers in phase 2 of the backpropagation are independent of each (error updates). Hence, we can run multiple workgroups for phase 2 - reducing bottlenecks and launching more threads.
Phase 2 can be shifted to a single update - with the layers running on seperate workgroups.
Modify the phase 2 dispatch code - instead of passing the layer and iterating over each layer - we pass the number of workgroups (which will represent the number of layers):
We also have to update the compute shader for phase 2 so it uses the
local_invocation_id
instead of the global one, since we have multiple smaller workgroups running instead of a single large one.
@compute @workgroup_size( MAX_NEURONS_PER_LAYER ) // >= than MAX_NEURONS_PER_LAYER
fn main2(@builtin(global_invocation_id) global_id: vec3<u32>,
@builtin(local_invocation_id) local_id: vec3<u32>,
@builtin(workgroup_id) workgroupId: vec3<u32> ) {
let g = local_id.x;
let k:u32 = workgroupId.x; // workgroup for each layer
// *2* Update Weights and Biases
// Update weights and biases for each layer using the error
//for (var k:u32=0; k<arrayLength( &layers )-1; k++) // -> shift to layer-by-layer compute calls
//let k:u32 = currentLayer;
{
//for (var g:u32=0; g<layers[k]; g++) // -> shift to threads
if ( g < layers[k] )
{
// Update the bias
var bias = getBias( k, g );
bias -= LEARNING_RATE * getError( k, g );
setBias( k, g, bias );
for (var n1:u32=0; n1<layers[k]; n1++)
//if ( n1 < layers[k] )
{
var weight = getWeight( k, g, n1 );
weight -= LEARNING_RATE * getError( k+1, n1 ) * getLayerOutput( k, g );
setWeight( k, g, n1, weight );
}
}
}
}// end main2
Reducing GPU Queue Stalls
At this point, we've been waiting for the GPU to finish it's work before passing in the next block - this is causing 'stalls'. We really want to GPU to be busy all the time - to have a packed queue of jobs ready to perform.
Hence, we'll comment out the line
await device.queue.onSubmittedWorkDone();
- which makes the code run substantially faster. This is where we start to see GPU neural network shine. As you ramp up the layers (and layer sizes) you'll see the compute version remains pretty constant - while the CPU (or single threaded compute) slows down and starts to chug along.