smallnn is a flexible neural network implementation with back propagation. It is 99 lines of C++, is free, simple and open source. The test case example
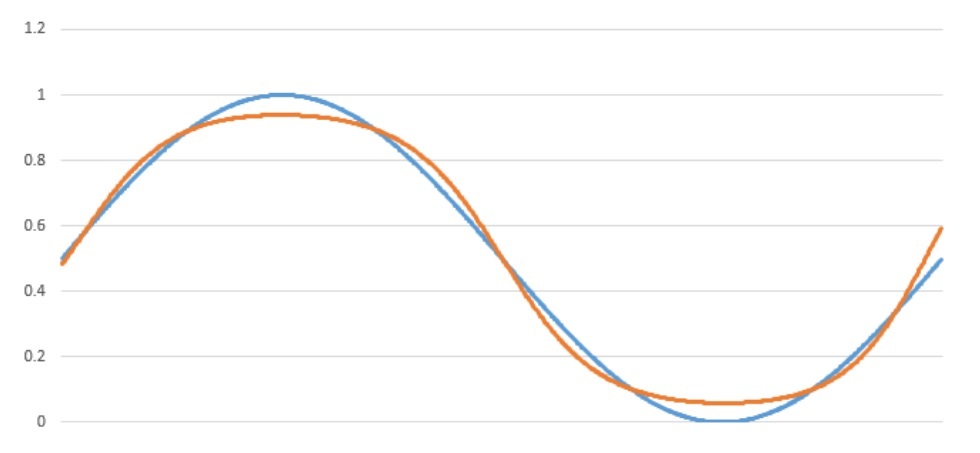
uses a 1-3-1 network configuration to emulate a sine wave function. As shown below in the illustration, you can see the ideal and the trained version of the output after 10,000 iterations.
• Neural network with back propagation training
• Support multiple layers - i.e., multilayer perceptron (MLP)
• Customizable (easy to configure for different topologies/layers/connections)
• Educational version (sometimes using libraries and packages masks the beauty of just how simple a neural network is at its heart)
• Not dependent on any libraries (vanilla C++)
• Importantly, it's a fun piece of code to play around with and learn about neural networks
Figure shows the result for training the neural network to emulate a sinewave (i.e., y=sin(x)).
You can see the implementation below, it might look a bit complex if you've not written a neural network before, but remember, this little
baby is customizable! Easy to modify and add new layers/nodes/topologies - I could have probably got it into 50 lines if I hardcoded the
beast! But I wanted to show a workable example that you could start with and expand.
#include <iostream>
#include <vector>
#include <map>
#include <math.h>
#include <time.h>
using namespace std;
#define TrainSetSize 20
#define PI 3.141592653589793238463
#define learn_rate 0.1
#define epoch 10000
double sigmoidF(double x) { return (1.0f / (1.0f + std::exp(-x))); }
double sigmoidB(double x) { return (sigmoidF(x) * (1.0 - sigmoidF(x))); }
double random(double min, double max) { return min + rand() / (RAND_MAX / (max - min + 1.0) + 1.0); }
struct neuron {
neuron() { id=rand(); bias=random(-1, 1); outputF=-1; outputB=-1; error=-1; }
int id;
double bias, error;
// incoming // outgoing
std::map<int, neuron*> incomingtargets; std::map<int, neuron*> outgoingtargets;
std::map<int, double > incomingweights; std::map<int, double > outgoingweights;
double outputF; // f(x) forward
double outputB; // f'(x) backward
void connect(neuron* n, double weight= random(-1, 1)) {
this->outgoingtargets[n->id] = n; n->incomingtargets[this->id] = this;
this->outgoingweights[n->id] = n->incomingweights[this->id] = weight;
}
double activate (double* input) {
if (input != NULL) {
this->outputB = 1; // f'(x)
this->outputF = *input; // f(x)
} else {
double sum = 0; // sum (x * w) + b
map<int, neuron*>::iterator it;
for (it = this->incomingtargets.begin(); it != this->incomingtargets.end(); it++){
sum += (this->incomingtargets[it->first]->outputF * this->incomingweights[it->first]);
}
sum += this->bias;
this->outputF = sigmoidF(sum);// f(x)
this->outputB = sigmoidB(sum);// f'(x)
}
return this->outputF;
}
double propagate(double* target, double rate = 0.3) {
double sum = 0;
if (target != NULL) {
sum = *target; sum = this->outputF - sum;
} else {
map<int, neuron*>::iterator it;
for (it = this->outgoingtargets.begin(); it != this->outgoingtargets.end(); it++) {
this->outgoingweights[it->first] -= rate * this->outgoingtargets[it->first]->error * this->outputF;
this->outgoingtargets[it->first]->incomingweights[this->id] = this->outgoingweights[it->first];
sum += this->outgoingtargets[it->first]->error * this->outgoingweights[it->first];
}}
this->error = sum * this->outputB; // delta error
this->bias -= rate * this->error; // delta bias
return this->error;
}
};
void main() {
srand((unsigned int)time(NULL));
neuron* inputs [] = { new neuron() }; // Input Layer w/ 1 neurons
neuron* hiddens[] = { new neuron(), new neuron(), new neuron() }; // Hiddent Layer w/ 3 neurons
neuron* outputs[] = { new neuron() }; // Output Layer w/ 1 neuron
// Connect Input Layer to Hidden Layer
inputs[0]->connect(hiddens[0]); inputs[0]->connect(hiddens[1]); inputs[0]->connect(hiddens[2]);
// Connect Hidden Layer to Output Layer
hiddens[0]->connect(outputs[0]); hiddens[1]->connect(outputs[0]); hiddens[2]->connect(outputs[0]);
vector<pair<double, double>> trainSet; trainSet.resize(TrainSetSize);
for (int i = 0; i < TrainSetSize; i++) { trainSet[i] = make_pair(i / (double)TrainSetSize, sin((i / (double)TrainSetSize) * (2.0 * PI))*0.5 + 0.5); }
for (int j = 0; j < epoch; j++) { double err = 0;
for (int k = 0; k < TrainSetSize; k++) {
// activate - passing information forward
double input = trainSet[k].first;
for (int i = 0; i < 1; i++) inputs[i]->activate(&input);
for (int i = 0; i < 3; i++) hiddens[i]->activate(NULL);
for (int i = 0; i < 1; i++) outputs[i]->activate(NULL);
// propogate - passing information backward (training/feedback/error)
double output = trainSet[k].second;
for (int i = 0; i < 1; i++) outputs[i]->propagate(&output,learn_rate);
for (int i = 0; i < 3; i++) hiddens[i]->propagate(NULL, learn_rate);
for (int i = 0; i < 1; i++) inputs[i]->propagate(NULL, learn_rate);
}
err += outputs[0]->error;
std::cout << err << ", " << j << "\r";
}
cout << "input, idea, predicted (y =sin(x))" << "\n";
for (int i = 0; i < 100; i++) { //Print out test results (ideal vs predicted for sin wave)
double input = i / 100.0;
for (int i = 0; i < 1; i++) inputs[i]->activate(&input);
for (int i = 0; i < 3; i++) hiddens[i]->activate(NULL);
for (int i = 0; i < 1; i++) outputs[i]->activate(NULL);
std::cout << (input) << ", " << sin(input * (2.0 * PI))*0.5 + 0.5 << ", " << outputs[0]->outputF << "\n";
} system("pause"); // wait for user to press a key before closing
}
Features
While the code seems compact, it's a great starting point! Some interesting things to try out:
1. Modify the activation function (change it to ReLU)
2. Try other test conditions, use other trigonometry functions (like cos and tan or even mixing them together to create complex signals)
3. The configuration is a 1-3-1, but try more complex ones (1-4-5-1 or 1-10-1)
4. Modify the epoch updates (compare the accuracy and time vs number of epochs) - plot the error vs number of epochs
5. Test out different learning rates
6. Optimize the learning rate so it's dynamic (changes based on the error/speed of convergence)
7. Try and 'optimize' the code so it runs faster, for instance, using OpenCL or C++ tricks
8. Modify the implementation so the topology and training data can be setup from a script (e.g., JSON file)
9. Add more visualization information to the program, so you can see things changing and updating in real time (adding GUI interface)
10. Try porting across various simple NN projects (e.g., image processing, recondition, text analysis, signal and animation) [link]
References:
1. Deep Learning with Javascript: Example-Based Approach (Kenwright) ISBN: 979-8660010767
2. Game C++ Programming: A Practical Introduction (Kenwright) ISBN: 979-8653531095
Visitor:
Copyright (c) 2002-2026 xbdev.net - All rights reserved.
Designated articles, tutorials and software are the property of their respective owners.